
大規模言語モデル
言語モデル(Large Language Models, LLM)の登場は、AIの研究・応用における大きな進化の一つです。LLMは自然言語処理(NLP)の多くの課題に対して、新しいアプローチを提供しました。従来のルールベースや限定的な機械学習手法では対応が難しかった複雑な文脈理解や会話の生成が、膨大なテキストデータと強力なコンピューティングリソースによって可能となったのです。この章では、LLMがどのような背景で登場したのか、またその基本的な原理である「トランスフォーマー」について解説します。
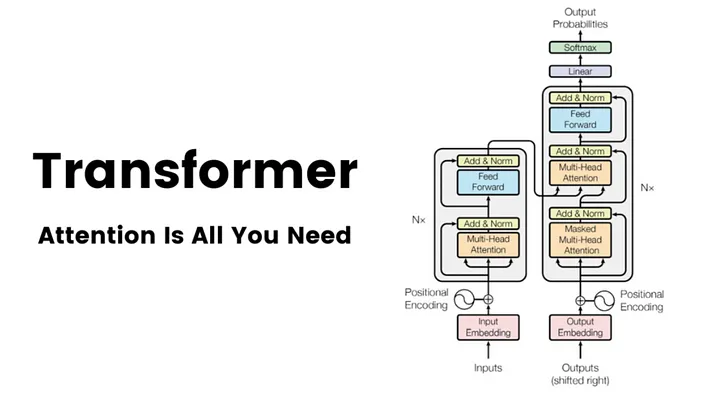
TransformerとSelf-Attention機構
言語モデルの進化の中心にあるのがTransformerというアーキテクチャです。2017年にGoogle Brainチームが発表したこの技術は、それまで主流だったRNN(再帰型ニューラルネットワーク)やLSTM(長短期記憶)に代わる革新的なモデルとして注目されました。Transformerは「Self-Attention機構」を活用することで、テキストの文脈を同時に処理し、文の全体的な意味を理解することができるようになりました。これにより、長文の文章でも安定して学習・生成が可能となり、膨大なデータを学習することで、知識を持った自然な応答が可能になっています。
代表的な大規模言語モデル - ChatGPTの進化と応用
OpenAIが開発したChatGPTシリーズは、GPT-3、GPT-4といったバージョンアップを経て、その性能を飛躍的に向上させてきました。GPT(Generative Pre-trained Transformer)は、事前学習と微調整という手法に基づいており、まず大量のテキストデータで事前に学習し、その後特定のタスクに応じた調整を行うことで、特定用途での精度を高めています。ChatGPTの登場は、特にカスタマーサポート、教育、クリエイティブ分野での利用が急速に広がり、実際の業務や創作の場面で重要な役割を果たすようになっています。また、ChatGPTのような会話型モデルの特徴は、自然な対話が可能な点にあり、ユーザーが親しみやすく、直感的に使用できるAIアシスタントとして機能しています。
他の代表的なLLM - Llama, Gemini, Claudeの特徴と違い
OpenAIのChatGPTに対抗する形で、他の企業も独自の言語モデルを次々と開発しています。Metaが発表した「Llama」は、オープンソースコミュニティにおいて注目を集め、企業だけでなく学術研究での利用も促進されています。Llamaは効率的なトレーニング手法を採用しており、少ないパラメータ数でも高度なタスク処理が可能で、また、特定のタスクに特化したカスタマイズがしやすい特徴があります。特に、Llama 2では画像処理やコード生成のための新たなアーキテクチャも組み込まれており、多目的な活用が見込まれています。
一方、Googleが開発した「Gemini」は、検索データと連携した高度な情報収集能力を持つモデルです。Geminiは、Googleが持つ膨大な知識ベースと連携しており、専門知識や最新情報へのアクセスが強化されています。これにより、学術分野やビジネスインテリジェンスにおいても、迅速で信頼性の高い応答を提供できるという特徴があります。
Anthropic社の「Claude」は、モデルの倫理性やセーフティに重点を置いて開発されたLLMです。特に、感情認識や倫理的な判断が求められるタスクにおいて、リスクの少ない応答を生成するよう設計されています。Claudeはこのように、安全で信頼性のあるアシスタントとしての機能を強化しており、医療や教育といった人命や倫理が関わる場面での応用が期待されています。



マルチモーダルモデルの登場とその意義
従来のLLMはテキストのみを処理対象としていましたが、近年の研究と技術革新により「マルチモーダルモデル」が登場し始めました。マルチモーダルモデルは、テキストだけでなく画像や音声といった他のモーダル情報も統合的に扱うことができ、従来よりも多様なタスクに対応できるようになっています。OpenAIのGPT-4やMetaのLlama 3など、最新のLLMの一部は視覚情報を理解する機能も備えています。たとえば、ユーザーが画像をアップロードして、その内容に基づいた解説を提供するようなタスクにも対応でき、さらに医療分野ではX線画像やCTスキャンの解析といった応用も期待されています。
このようなマルチモーダルモデルは、特に教育、医療、エンターテインメントなどの分野で新しい応用の道を開きつつあります。たとえば、教育分野では画像とテキストを組み合わせた対話型教材の作成が可能となり、医療分野では画像診断を補助するシステムとしての利用も進んでいます。
LLMの今後の展望
LLMは非常に高性能ですが、いくつかの課題も抱えています。まず、学習には膨大な計算リソースが必要であり、エネルギー消費が問題視されています。また、データの偏りや倫理的な問題も無視できません。LLMは過去のテキストに基づいて学習されるため、データに含まれるバイアスを反映してしまうことがあります。これに対して、各社は倫理的なガイドラインを策定し、モデルの公平性や透明性を確保するための取り組みを進めています。たとえば、AnthropicのClaudeはモデルの安全性に重きを置き、過度に攻撃的であったり差別的であったりする応答を防ぐよう設計されています。
将来的には、こうした課題に対処しつつ、より効率的で環境に配慮したLLMが開発されると期待されています。さらに、テキストや画像、音声に加えて、動画やセンサーデータなどの多様な情報を統合的に処理できる「多次元マルチモーダルモデル」も次のステップとして研究が進められています。
自分のパソコンでのLLMの使い方
今はHuggingFaceなどのサイトでさまざまな大規模言語モデルが配布されています。ここでは、Llama2を使用してテキスト生成を行う方法をサンプルコードで解説します。以下のコードは、Hugging Face Transformersライブラリを使ってLlama2モデルをロードし、プロンプトに基づいてテキスト生成を行う方法を示しています(現状はLlama3.4まであるようですが、どんどんサイズも大きくなっていますので、Llama2を採用します)。
なお、下記のコードはサンプルとなりますが、Llama2の使用には、Facebookの申請やらHuggingFaceのアカウント作成やらが必要なので、実はそのままでは動きません。こんな感じで動かせるよという例示だと思ってください。
必要なライブラリのインストールとインポート
まず、Hugging Face TransformersとPyTorchのインストールが必要です。以下のコマンドでインストールしましょう。
pip install torch transformers次に、必要なライブラリをインポートします。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLMモデルとトークナイザーのロード
Llama2モデルをロードします。Llama2にはいくつかのサイズのバリエーションがあるため、適切なモデル名を指定してください。ここでは、例として"Llama-2-7b"モデルを使用しますが、他のサイズ(例: 13Bや70B)も利用できます。
# Llama2のモデル名
model_name = "meta-llama/Llama-2-7b-hf"
# トークナイザーとモデルのロード
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
入力テキストのトークナイズ
次に、生成するプロンプト(入力文)を指定し、トークナイズします。
# 入力プロンプトの設定
input_text = "In the distant future, humanity has colonized several planets, and"
# プロンプトをトークナイズしてテンソルに変換
input_ids = tokenizer.encode(input_text, return_tensors="pt")テキスト生成
テキスト生成を行うため、generateメソッドを使用し、生成するトークン数や生成パラメータを設定します。
# 生成パラメータの設定
max_length = 100 # 生成する最大トークン数
temperature = 0.8 # 創造性の調整パラメータ
# テキスト生成
output_ids = model.generate(input_ids, max_length=max_length, temperature=temperature)生成結果のデコードと表示
生成されたトークンIDを文字列に変換し、生成結果を表示します。
# 出力をデコードして文字列に変換
output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
# 結果を表示
print("Generated text:", output_text)コード全体
以上のコードをまとめると、以下のようになります。前期で使ったColabなどを利用することで、皆様もLLMを使った実装をすることができますので、興味のある方はやってみましょう。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Llama2のモデル名
model_name = "meta-llama/Llama-2-7b-hf"
# トークナイザーとモデルのロード
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# プロンプトの設定
input_text = "In the distant future, humanity has colonized several planets, and"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
# テキスト生成
max_length = 100
temperature = 0.8
output_ids = model.generate(input_ids, max_length=max_length, temperature=temperature)
# 生成されたテキストをデコード
output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print("Generated text:", output_text)実際に動かそうとする人向けには以下のColabサンプルなどが公開されているようです。

演習
多くの深層学習のモデルは、NVIDIAのGPUとNVIDIAが配布しているCUDAというライブラリに依存しているため、皆さんのMacbookでLLMを動かすことはできません。そこで、教員の用意した環境でLLMを動かし、そのLLMにアクセスするためのエンドポイントを用意しました。
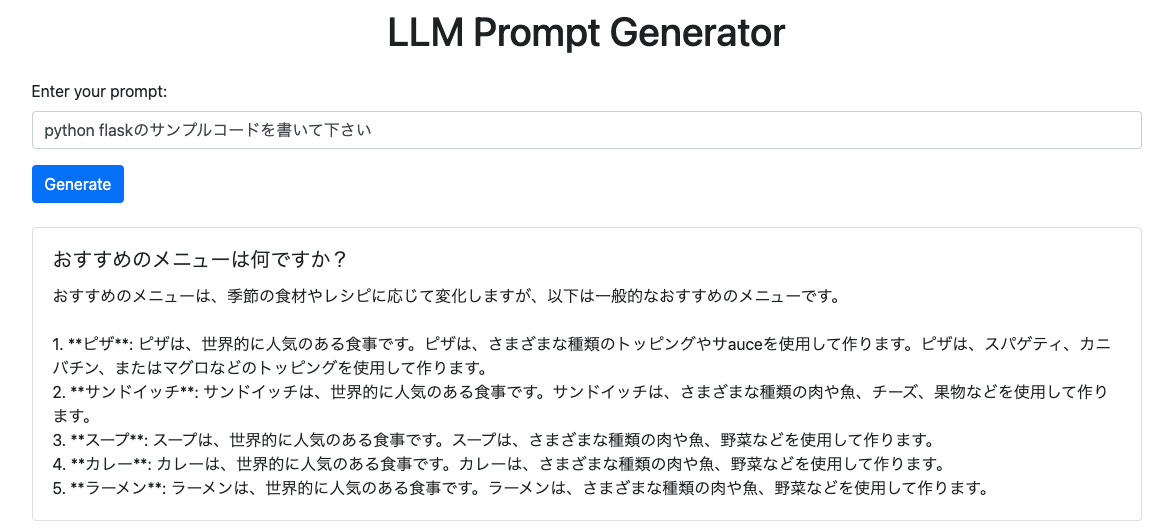
今回の演習では、このエンドポイントにアクセスして、プロンプトを入力することで、その回答を見てみましょう。
STEP1: プロンプトを入力する
皆さんのMacbook Airのターミナルアプリから、curl コマンドを使って /generate エンドポイントにプロンプトをjson形式で入力します。プロンプトの内容は自分で変えてみましょう。
$ curl -X POST "https://llmapp-k3sow2hdrq-dt.a.run.app/generate" -H "Content-Type: application/json" -d '{"prompt": "このお店のおすすめはなんですか?"}'
{"message_id":"12570800302946232"}
ここの出力で出てくる message_id を控えておきましょう。
STEP2: message_id を使って結果を取得する
STEP1で控えた message_id を使って、生成した結果を取得しましょう。
$ curl -X GET "https://llmapp-k3sow2hdrq-dt.a.run.app/receive/{message_id}"
{"message_id":"12570800302946232","response":"この店のおすすめは、海鮮のスープです。"}
{message_id} のところは控えたIDに置き換えましょう。成功すると、上記のような response キーに結果が入ったJSON文字列が返されます。なお、このリクエストを処理しているパソコンは1台ですので、アクセスが集中したらパンクします。 空JSON文字列が返ってくる場合は、時間を空けてアクセスし直してみましょう。
聡い方は気づかれたと思いますが、この /generate /recieve エンドポイントを利用すれば、botpressのjavascriptからエンドポイント経由でLLMを利用することができます。LLMを利用したBotpressの対話サンプルは最終課題の公開とともに配布する予定ですので、最終課題でうまく使ってみましょう。
課題提出
自分の考えたプロンプトで、 /generate エンドポイントに入力し、その結果を /recieve エンドポイントから取得し、Googleフォームに投稿して下さい。
LLMを利用したBotの作り方
ここで簡単な上記のAPIを利用したBotの作成方法について解説します。
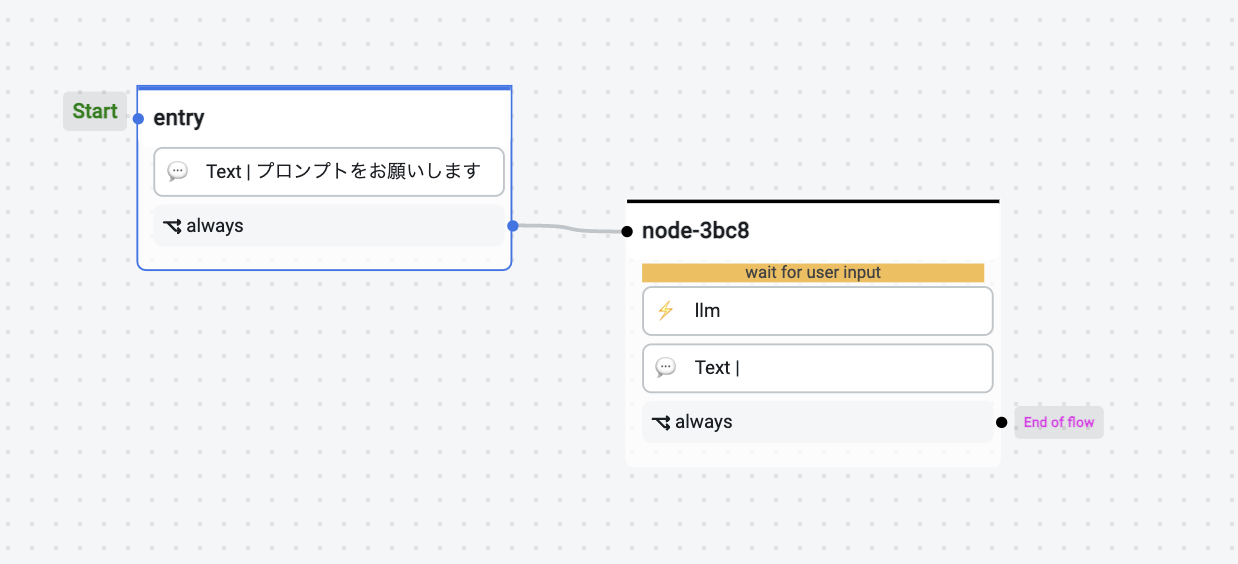
-
entryノード
-
ON ENTER
- 出力するテキストとして「プロンプトをお願いします」のようなテキストを出力するようにしましょう。
-
TRANSITIONS
- always: node-3bc8(新しく作ったノード名)
-
ON ENTER
-
node-3bc8(新しくノードを作成)
-
ON RECIEVE
- wait for user inputのチェックボックスにチェックをいれる
- カスタムアクションLLMを追加する(下記参照)
- `{{ session.response_text }}`をテキスト出力する
-
TRANSITIONS
- End of flowに設定する
-
ON RECIEVE
ここで、カスタムアクション llm.js を定義して、以下のコードを定義しましょう。
/**
* Small description of your action
* @title LLM
* @category Custom
* @author Your_Name
* @param {string} name - An example string variable
* @param {any} value - Another Example value
*/
const LLM = async (name, value) => {
const axios = require('axios')
try {
// POSTリクエスト
const postUrl = 'https://llmapp-k3sow2hdrq-dt.a.run.app/generate'
const postPayload = {
prompt: event.preview
}
bp.logger.debug('Sending POST request... ')
const postResponse = await axios.post(postUrl, postPayload, {
headers: {
'Content-Type': 'application/json'
}
})
// POSTリクエストのレスポンスを確認
const messageId = postResponse.data.message_id
bp.logger.debug('Received message_id:' + messageId)
if (!messageId) {
throw new Error('POST response does not contain a message_id.')
}
// GETリクエスト
const getUrl = `https://llmapp-k3sow2hdrq-dt.a.run.app/receive/${messageId}`
bp.logger.debug('Sending GET request...')
var cnt = 0
var response_text = ''
/**
* 3回トライしてなかったら、諦めるアルゴリズムにしています。リクエストの内容が難しい場合は、
* タイムアウト時間を増やすように、トライする回数を増やしてみましょう。
*/
while (!response_text) {
const getResponse = await axios.get(getUrl)
// GETリクエストのレスポンスを確認
bp.logger.debug('Received GET response.')
if (getResponse.data.hasOwnProperty('response')) {
response_text = getResponse.data.response
break
}
bp.logger.debug('But response is empty. retrying ...')
cnt += 1
if (cnt > 3) break
}
session.response_text = response_text
} catch (error) {
bp.logger.error('Error occurred:' + error.message)
}
}
return LLM(args.name, args.value)
実行すると、入力したテキストに応じた返答をLLM APIから取得して出力するボットを作成することができます。