
音声対話アプリ利用説明
最終課題では皆さんが作成された会話モデルを、音声入出力可能なチャットアプリを通して検証してもらいます。
本資料では、そのチャットアプリの設定とデプロイの方法を説明します。
Safariでは動作確認していないので、必ずChromeでアクセスしてください
音声対話機能の拡張
ここでは、対話システム1で取り扱ったChatbotを例に音声対話機能の拡張方法を解説します。
ブラウザの設定
音声の自動再生を有効にするため、Chromeの設定を変更します。
(画面のChromeの設定画面は少し古いですが、設定の方法はそれほど変わりません)
-
Chromeのメニューから『設定』を選択
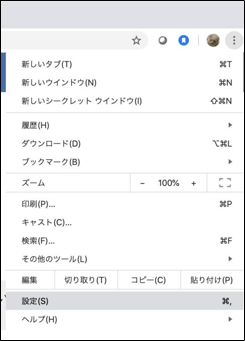
-
『設定』画面の検索窓に「音声」と入力すると、『サイトの設定』が検出されるのでクリック
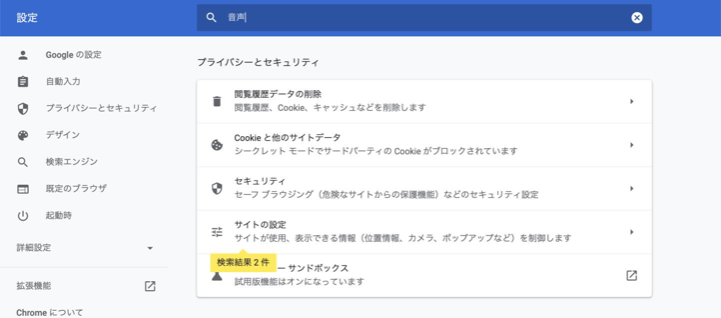
-
『その他のコンテンツの設定』を展開して『音声』をクリック

-
『音声の再生を許可するサイト』の『追加』をクリック

-
自分のアプリURLを入力し、『追加』をクリック
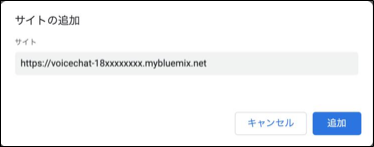
対話システム1のNodeREDの改造
Google Classroom「水曜3-4限 情報メディアプロジェクトII 2023」の「第10〜15回最終課題」→「資料③ 最終課題補足資料」のvoicechat.htmlをダウンロードして、対話システム(基本編)で作成したフローを真似て、以下のような構成にしてください。

-
http inとして、/voicechatで待ち受けける -
templateに上記のvoicechat.htmlを登録する
デプロイしたら、
- http://localhost:1880/voicechat
にアクセスして、挙動を確認しましょう。
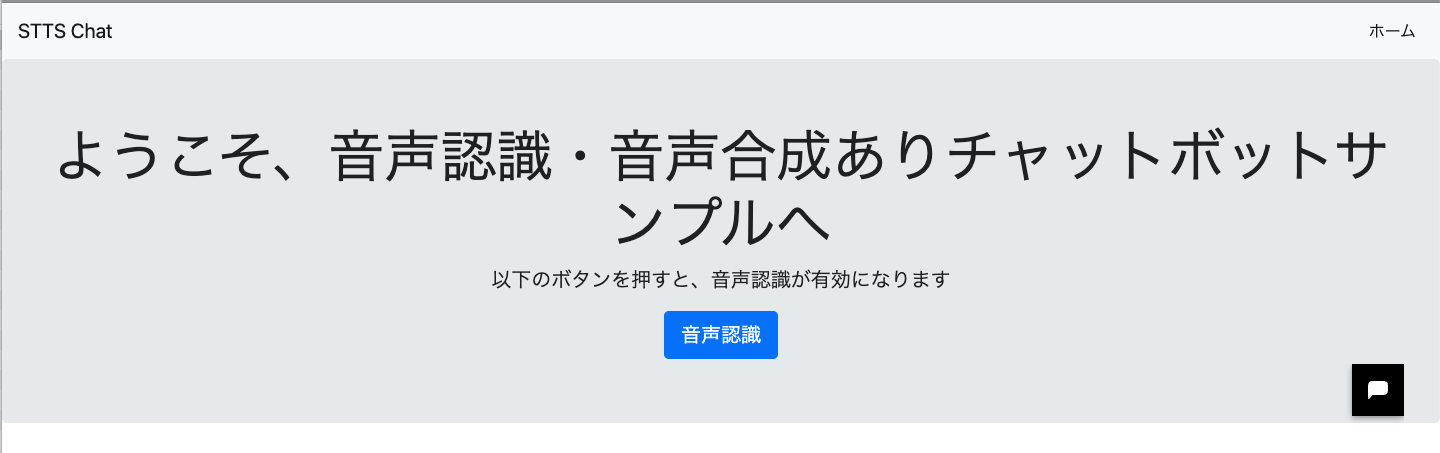
デプロイに成功していれば、上記のように対話システム(基本編)のサイトの内容が変更します。「音声認識」ボタンを押すと「マイク」へのアクセスを許可するかの確認ウィンドウが出てきますので、許可してください。
許可すると音声認識のボタンが赤くなり、音声認識を開始します。対話システムの対話内容を発話すると、あなたに変わって、サイトが音声認識をして、認識した文字を打ち込んでくれます。

もう一度、「音声認識」ボタンをクリックすると、音声認識のプロセスがストップします。
音声合成・認識の仕組み
この音声合成、認識の仕組みは、voicechat.html 中 の javascript の部分で実現されています。以下、要素ごとにその機能の実装について解説します。
-
Toast通知の作成: ユーザーに情報を提供するためのポップアップ通知(Toast)のHTMLを生成しています。
var toastHtml = ` <div class="toast" role="alert" aria-live="assertive" aria-atomic="true" data-delay="15000"> <div class="toast-header"> <strong class="mr-auto">STT</strong> <button type="button" class="ml-2 mb-1 close" data-dismiss="toast" aria-label="Close"> <span aria-hidden="true">×</span> </button> </div> <div class="toast-body"> ###MESSAGE### </div> </div>`; ... // Toastをコンテナに追加 $('#toastContainer').append( toastHtml.replace( '###MESSAGE###', '音声認識に失敗しました。もう一度発話してください' ) ); // Toastを表示 $('.toast').toast('show'); // 15秒後にToastを自動的に削除 setTimeout(function(){ $('.toast').toast('dispose').remove(); }, 15000); -
Botpress Web Chatの初期化:
window.botpressWebChat.initを使用して、特定のホストとボットIDを指定してBotpressのWebチャット機能を初期化しています。// Botpressを有効化する window.botpressWebChat.init({ host: "http://localhost:3000", botId: "foodbot" }); -
音声同期再生の実装:
syncplay関数は、与えられたオーディオ要素を再生し、その終了を待つためのPromiseを返します。// 音声の同期再生を実装 const syncplay = (audio) => { return new Promise(res=>{ audio.play(); audio.onended = res; }) } -
音声合成の実装:
playAudio関数は、与えられたテキストを使用して音声合成を行い、その音声を再生します。音声合成は外部APIを利用しています。// 実習用の音声合成サイトのAPIを使って、音声合成を行う const playAudio = async (text) => { var audio = new Audio(); var downloadURL = 'https://kdix-media-project-sfkbku37lq-dt.a.run.app/tts/convert?gender=1&input_type=1&text=' + encodeURIComponent( text.replace(/<br>/g,'\n') ); audio.pause(); audio.src = downloadURL; return await syncplay(audio); } -
音声再生のためのキュー処理:
QueueProcessorクラスは、音声を順番に再生するためのキューを管理します。キューに音声が追加されると、順番に再生されます。class QueueProcessor { constructor() { this.queue = []; this.isProcessing = false; } // キューに要素を追加し、処理がまだ行われていない場合は処理を開始する enqueue(item) { this.queue.push(item); if (!this.isProcessing) { this.processQueue(); } } // キューの要素を順番に処理する async processQueue() { this.isProcessing = true; while (this.queue.length > 0) { const item = this.queue.shift(); await playAudio(item); } this.isProcessing = false; } // 個々の要素を処理する(サンプルの非同期関数) async processItem(item) { console.log(`処理中: ${item}`); // ここで何らかの非同期処理を行う await new Promise(resolve => setTimeout(resolve, 1000)); // 例: 1秒の遅延 } } // 音声合成をするためのテキストを保持するキューインスタンスを生成 const processor = new QueueProcessor(); -
メッセージ処理:
$(window).on('message', ...)は、ウィンドウで発生するmessageイベントを処理します。特定の条件に基づいて、音声合成を行いキューに追加するかどうかを決定します。// メッセージに対する処理を定義 $(window).on('message', () => { // console.log(JSON.stringify(event.data)); if (event.data.hasOwnProperty('authorId')) { // 発話が自分がしたものなら、パスする } else if (event.data.hasOwnProperty('payload') && event.data.payload.hasOwnProperty('type') && event.data.payload.type === 'session_reset' ) { // セッションのリセットメッセージの場合、何もしない } else if (event.data.hasOwnProperty('payload') && event.data.payload.hasOwnProperty('text') ) { // ボットからのメッセージの場合は、音声合成して再生する var message = event.data.payload.text; console.log(message); processor.enqueue(message); } }); -
音声認識の準備: ユーザーのメディアデバイス(主にマイク)へのアクセスを設定し、必要なAPIを確認します。
/** * 使用可能メディアの確認 */ navigator.getUserMedia = navigator.getUserMedia || navigator.webkitGetUserMedia || navigator.mozGetUserMedia || navigator.msGetUserMedia; window.URL = window.URL || window.webkitURL || window.mozURL || window.msURL; window.AudioContext = window.AudioContext|| window.webkitAudioContext; -
音声認識の実装:
startConversationとterminateConversation関数は、音声認識の開始と終了を管理します。ユーザーが音声入力を開始・停止できるようにボタンの挙動も定義されています。// 音声合成ボタンの挙動を定義 $('#stt_btn').click(() => { if (!onConversation) { // ボタンが青の時にクリックすると、音声認識を開始 startConversation(); onConversation = true; } else { // ボタンが赤の時にクリックすると、音声認識を停止 terminateConversation(); onConversation = false; } }); ... const startConversation = () => { console.log("start conversation"); navigator.mediaDevices.getUserMedia( {video: false, audio: true} ).then((stream) => { console.log("play button clicked"); mediaRecorder = new MediaRecorder(stream); mediaRecorder.start(); mediaRecorder.ondataavailable = function (e) { mimeType = e.data.type; console.log(mimeType); chunks.push(e.data); }; mediaRecorder.onstart = onMediaRecorderStart; mediaRecorder.onstop = onMediaRecorderStop; /* ここからは音声の区間検出を行う実装。以下のサイトを参考にして構築した。 https://stackoverflow.com/questions/71103807/detect-silence-in-audio-recording */ audioContext = new AudioContext(); audioStreamSource = audioContext.createMediaStreamSource(stream); const analyser = audioContext.createAnalyser(); analyser.minDecibels = MIN_DECIBELS; audioStreamSource.connect(analyser); const bufferLength = analyser.frequencyBinCount; const domainData = new Uint8Array(bufferLength); // domainDataのsumがこの閾値を超えたら有音、超えなかったら無音区間とする let silenceSumThreshold = 100; // 区間チェックする単位時間 let waitInterval = 100; // 開発環境で1秒程度。 var soundDetected = false; var silenceCount = 0; /** * 収録した音の大きさをチェックし、有音区間・無音区間を検出する。 */ const detectSound = () => { analyser.getByteFrequencyData(domainData); var decsum = domainData.reduce((a,b) => a+b, 0); if (decsum <= silenceSumThreshold) { silenceCount += 1; } else if (decsum > silenceSumThreshold) { soundDetected = true; silenceCount = 0; console.log("voice detected"); } if (soundDetected && silenceCount > waitInterval) { console.log("voice section end. gonna post sound ..."); mediaRecorder.stop(); // initialize parameters; soundDetected = false; silenceCount = 0; mediaRecorder.start(); } else if (silenceCount > waitInterval) { silenceCount = 0; restart_mediarecorder = true; mediaRecorder.stop(); } // console.log("audio ended"); if (!do_not_repeat_detectsound) { window.requestAnimationFrame(detectSound); } else { do_not_repeat_detectsound = false; } }; window.requestAnimationFrame(detectSound); }).catch(function (e) { alert(e); }); } const terminateConversation = () => { console.log('terminate conversation'); // if(audio !== null && !audio.ended) { // audio.pause(); // } terminate = true; $('#stt_btn').css('display', 'inline'); do_not_repeat_detectsound = true; audioStreamSource.disconnect(); audioContext.close(); terminate = true; mediaRecorder.stop(); // document.querySelector('#stop').click(); } -
メディアレコーダーの挙動の定義: 音声の録音を開始・停止する際の挙動を定義しています。録音された音声は、音声認識APIに送信され、処理されます。
// メディア(音声)レコーダのスタート時の挙動を定義。ボタンを赤にする const onMediaRecorderStart = () => { console.log('on start'); $('#stt_btn').css('background-color', '#d74108'); }; /** * メディア(音声)レコーダの停止時の挙動を定義。 * * メディアレコーダは有音区間を検出するために、定期的に再生成される。 * そのため、停止の挙動は以下のように分かれる * * - terminateフラグが立っている時:停止する * - それ以外、media recorderインスタンスを再生成して、スタートする */ const onMediaRecorderStop = () => { console.log('on stop'); // 音声認識ボタンを青にする $('#stt_btn').css('background-color', '#466bb0'); if (terminate) { console.log("gonna terminate"); terminate = false; return; } /** * 無音区間は、定期的にメディアレコーダを再起動する。 * そうしないと、無音区間ごと音声認識APIに送られてしまう。 */ if (restart_mediarecorder) { console.log('nothings to do. gonna leave on stop'); chunks = []; restart_mediarecorder = false; mediaRecorder.start(); return; } // ここから録音した音声を使った音声認識を行う const blob = new Blob(chunks, {'type': mimeType}); chunks = []; // POSTするデータの作成 var fd = new FormData(); fd.append('speech', blob, 'recorded.webm'); fd.append('engine', "3"); fd.append('mimetype', "2"); // 音声データのポスト $.ajax({ url: 'https://kdix-media-project-sfkbku37lq-dt.a.run.app/stt', type: "POST", data: fd, processData: false, contentType: false, dataType: 'json', }).done((response) => { // 認識結果が返ってきた時の処理 console.log(response); if (!('results' in response)) { console.log("no recognition results"); // Toastをコンテナに追加 $('#toastContainer').append( toastHtml.replace( '###MESSAGE###', '音声認識に失敗しました。もう一度発話してください' ) ); // Toastを表示 $('.toast').toast('show'); // 15秒後にToastを自動的に削除 setTimeout(function(){ $('.toast').toast('dispose').remove(); }, 15000); return; } // 音声認識が成功した場合は、ユーザの代わりにPayloadをbotpressサーバに送信 console.log('detected utterance: ' + response.results[0].alternatives[0].transcript); window.botpressWebChat.sendPayload({ type: "text", text: response.results[0].alternatives[0].transcript }); }).fail((XMLHttpRequest, textStatus, errorThrown) => { console.log("XMLHttpRequest : " + XMLHttpRequest.status); console.log("textStatus : " + textStatus); console.log("errorThrown : " + errorThrown.message); } ); }; -
音声区間の検出:
onMediaRecorderStopで連続する音声の区間を検出し、無音区間ではメディアレコーダーを再起動することで、効率的な音声認識を実現しています。
このコードは、音声入力と出力を含む対話型のWebアプリケーションのためのものであり、ユーザーの発話を認識し、適切な応答を音声合成で返す機能を持っています。また、Toast通知を使ってユーザーにフィードバックを提供する機能も含まれています。