
音声合成
音声合成とは?
機械やコンピューターなどを利用して音声を人工的に生成する技術
- テキスト(文章)を音声に変換できることから、しばしばテキスト読み上げ(text-to-speech、略してTTS)システムとも呼ばれる
- 録音編集方式、分析合成方式、テキスト合成方式などがある
- 音声合成を行うシステムをスピーチ・シンセサイザー(Speech synthesizer)、音声合成で生成した音声を合成音声と呼ぶ
- 発音記号を音声に変換するシステムもある
音声合成の例
入力したテキストを読み上げさせて文章の校正に用いたり、電話を介しての情報サービス、視覚障害者用読書器のような福祉機器などに用いられている。
高品質化と小型化・低価格化が進めば、オフィスや家庭のコンピュータのインターフェースとしての利用が期待される。
ユースケース
音声合成を使用すると以下のようなアプリケーションを構築することが可能
-
電子辞書読み上げ
- 多様なテキストの音声を簡単かつ動的に作成することが可能
- 文章の読み上げや、単語等の発音の確認機能として利用
-
家電・OA機器
- 操作ガイダンスを音声で行う音声ヘルプとして利用
-
車載機器
- カーナビ、ETC装置、レーダー探知機、計装機器、タクシーメータ、渋滞情報など刻々変化する情報の読み上げ
-
展示説明や街角情報端末
- 手持ちの携帯電話やスマートフォンをかざすことで音声ガイドを行う
使用可能な音声合成サービス
複数のクラウドベンダーが音声合成のAPIサービスを提供している
- Amazon Polly (Amazon Web Service)
- Text to Speech API (Microsoft Azure)
- Cloud Text-to-Speech (Google Cloud)
- Text to Speech (IBM Watson)
音声認識
音声認識とは?
人間の声などをコンピューターに認識させ、話し言葉を文字列に変換したり、音声の特徴をとらえて声を出している人を識別する技術
- 音声認識とは、人間の声などをコンピューターに認識させること
- 話し言葉を文字列に変換したり音声の特徴をとらえて声を出している人を識別したりする機能を指す
- 話し言葉を文字列に変換する機能は、指を用いてキーボードから入力する方法に代わるものである
- 音声を理解し、文章を書き出す機能を「音声入力」あるいは「ディクテーション(聞き取り)」と言う
- キーボード使いアプリケーションを操作するように、音声認識でアプリケーションを操作する機能を「音声操作」と言う
音声認識の例
- 音声認識は人間の音声をコンピューターが自動的に認識する
- 音声の理解だけでなく、キーボードやマウスに代わる新しい操作方法として研究が行われ、実用化が進められている
- 認識技術としては、統計的手法、動的時間伸縮法、隠れマルコフモデルがある
ユースケース
音声認識を使用すると以下のようなアプリケーションを構築することが可能
-
字幕作成
- 記者会見や生放送番組などの字幕をリアルタイムに作成する
-
コールセンター業務
- 問い合わせの電話をリアルタイムで文章に書き起こし、FAQ対応の支援を行う
-
英語教育支援
- 英文を読み上げる音声を解析し、おかしな発音の箇所を指摘する
-
議事録作成
- 会議の音声を解析し、誰がどのタイミングで何を話したかを文章化し、議事録を作成する
使用可能な音声認識サービス
複数のクラウドベンダーが音声認識のAPIサービスを提供している
クラウドで利用できる音声認識API
- Speech to Text (IBM Watson)
- Amazon Transcribe (Amazon Web Service)
- Speech to Text (Microsoft Azure)
- Cloud Speech-to-Text API (Google Cloud)
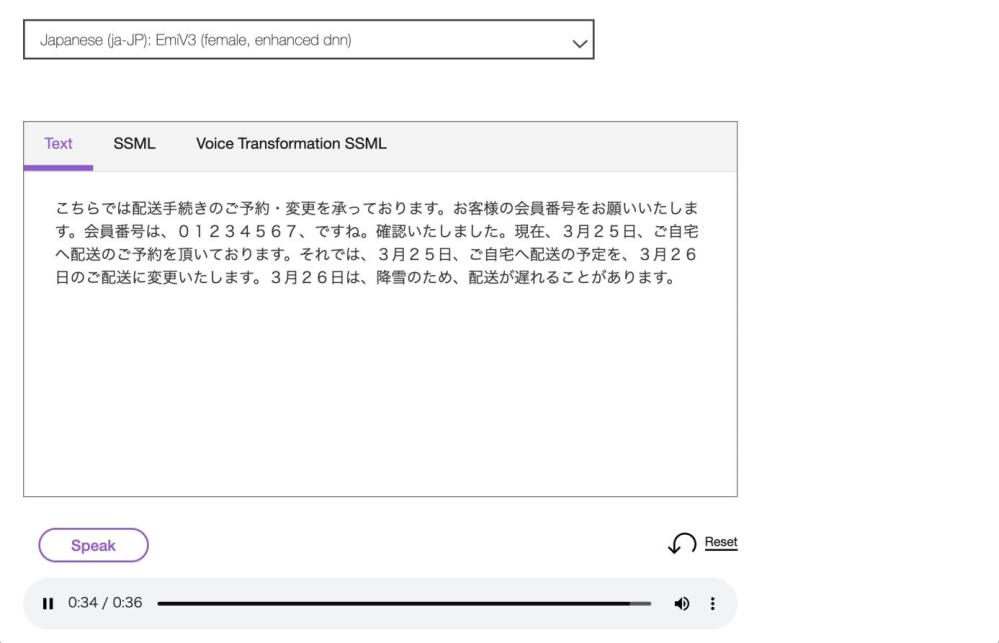
音声合成実習
SSMLを編集して、読み上げ方を色々とカスタマイズしてみよう。
音声合成マークアップ言語(SSML)
音声合成においてテキスト解析を100%正しく行うことは困難である。また、テキストからは解釈できない、特定の読み方をさせたいこともある。そこで何らかの方法により情報を指定する必要があるが、W3Cにより定義された音声合成マークアップ言語 (Speech Synthesis Markup Language; SSML) により行う方法がある。
どんなときに使うのか?
例:日本にはそのままでは読めない地名・駅名が多くある。以下、大阪の駅名から難読なものをいくつかピックアップした。
- 十三:じゅうそう
- 柴島:くにじま
- 放出:はなてん
- 日本橋:にっぽんばし
このような難読な駅名をしっかりと読み上げさせるためにSSMLを使います。
SSMLを利用した音声合成の指示
例えば以下の文章をSSMLを使って駅名を間違えさせずに、読み上げさせてみましょう。
日本には多くの読みがわからない駅名が存在する。
例えば、大阪には、十三、柴島、放出、日本橋といった駅名が存在する。<speak>
日本には多くの読みがわからない駅名が存在する。例えば、大阪には、
<sub alias="じゅうそう">十三</sub>、<sub alias="くにじま">柴島</sub>、
<sub alias="はなてん">放出</sub>、<sub alias="にっぽんばし">日本橋</sub>
といった駅名が存在する。
</speak>実際にやってみよう
https://kdix-media-project-sfkbku37lq-dt.a.run.app/tts
主なSSML tag: break
<break>
休止、または韻律のその他の単語間の境界を制御する空の要素。トークンのペアの間で <break> を使用するかどうかは任意です。この要素が単語間に存在しない場合、言語的コンテキストに基づいて自動的にブレークが決定されます。
例
次の例は、<break> 要素を使用してステップ間で休止する方法を示します。
<speak>
Step 1, take a deep breath. <break time="200ms"/>
Step 2, exhale.
Step 3, take a deep breath again. <break strength="weak"/>
Step 4, exhale.
</speak>主なSSML tag: sub
<sub>
- 発音の際、タグ内のテキストが alias 属性値のテキストによって置き換えられることを示します。
- sub 要素を使用して、読みにくい単語の簡略化された発音を提供することもできます。下の最後の例は、日本語でのこのユースケースを示しています。
-
例
<sub alias="World Wide Web Consortium">W3C</sub>
他にも色々あるので、詳しくは以下を参照しながらカスタマイズしましょう。
https://cloud.google.com/text-to-speech/docs/ssml?hl=ja
課題
以下の文を読み上げ文のように読めるように、SSMLを編集して意図通りに音声合成されるか試しましょう。読み替えだけでなく、適切に間を入れて、聞き取りやすいように工夫してみましょう。
元にする文章
本実習では、音声合成(TTS)について解説した。全体としては、
1. 音声合成について
2. SSMLについて
の大きく2つを解説し、演習によってその効果を確かめた。読み上げ文
本実習では、音声合成、Text to Speech、について解説した。
全体としては、まず、音声合成について、
次に、SSMLについて
の大きく2つを解説し、演習によってその効果を確かめた。音声認識 実習
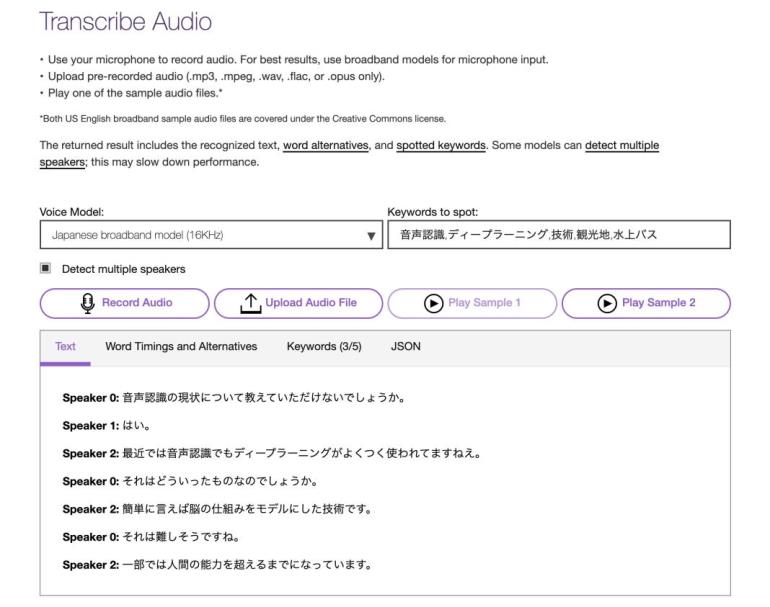
現在、使用できる音声認識ソフトウェアについて知ろう。今日の演習で試す音声認識ソフトウェアは以下の通り。
- Julius
- Kaldi
- Google Cloud/Speech to Text API
以下それぞれ解説します。
Julius: 日本発の音声認識ソフトウェア
Julius は,音声認識システムの開発・研究のためのオープンソースの高性能な汎用大語彙連続音声認識エンジンである. 数万語彙の連続音声認識を一般のPCやスマートフォン上でほぼ実時間で実行できる軽量さとコンパクトさを持っている.
言語モデルとして単語N-gram,記述文法,ならびに単語辞書を用いることができる.また音響モデルとしてトライフォンのGMM-HMMおよびDNN-HMMを用いたリアルタイム認識を行うことができる.DNN-HMMの出力計算にnumpyを用いた外部モジュールを利用することも可能で複数のモデルや複数の文法を並列で用いた同時認識も行うことができる.
Juliusの最大の特徴はその可搬性にある.単語辞書や言語モデル・音響モデルなどの音声認識の各モジュールを組み替えることで,小語彙の音声対話システムからディクテーションまで様々な幅広い用途に応用できる.
Kaldi: 深層学習モデルの音声認識ソフトウェア
音声認識ツールキットKaldiは、様々な最新の音声認識技術に対応した音声認識の基盤ソフトウエアである。国際的な研究者コミュニティにより活発な開発が行われており、オープンソースとして公開されている。Kaldiでは音声や統計モデルの操作のための各種コマンドに加えて、様々なコーパスに対してほぼ全自動で認識システムを構築し認識実験を行うためのスクリプト(レシピ)が用意されている。

Google Cloud:Speech to Text
Google による AI の研究とテクノロジーを最大限に活用した API を利用し、音声を正確にテキストに変換できる。Google 最新のディープ ラーニング ニューラル ネットワーク アルゴリズムを利用して、自動音声認識(ASR)を実現しており、Speech-to-Text UI でカスタム リソースのテスト、作成、管理を行うこともできる。
音声認識に使われている技術の進化
画像はここから抜粋 https://ys0510.hatenablog.com/entry/e2e_asr

課題
これまで挙げた3つの音声認識ソフトウェアで音声認識をしてみて、その性能を比較してみよう
- Julius
- Kaldi
- Google Cloud/Speech to Text API
実際にやってみよう
https://kdix-media-project-sfkbku37lq-dt.a.run.app/stt
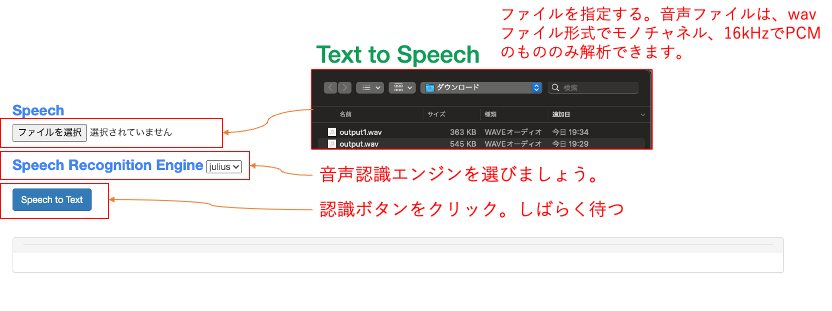
Julius: Speech Recognition Engineで”julius”を選びましょう
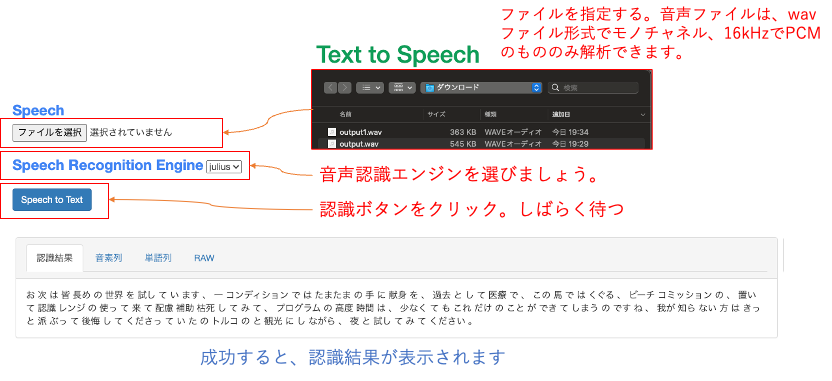
Kaldi: Speech Recognition Engineで”kaldi”を選びましょう
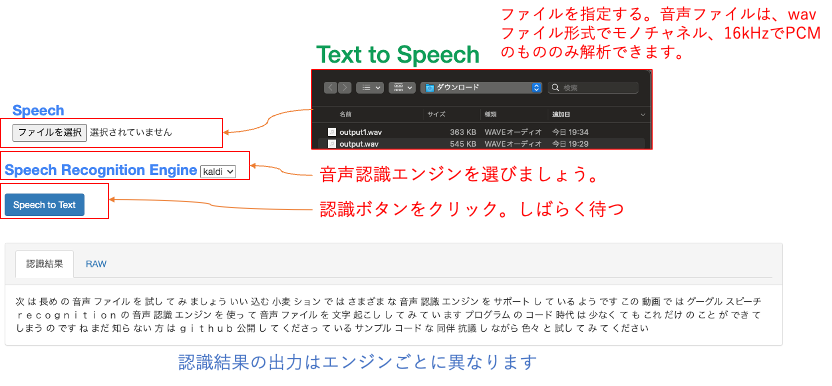
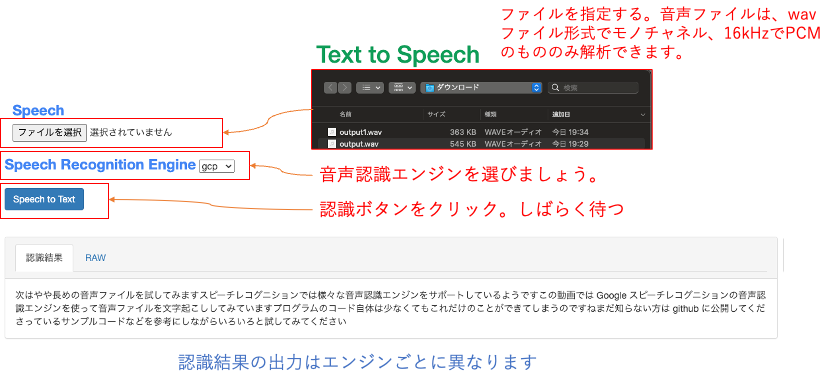
GCP: Speech Recognition Engineで”gcp”を選びましょう
課題詳細
- 課題1 :voice.wavを入力して、エンジンごとの認識結果の違いを確認しよう。
- 課題2 :実習1で作った音声合成のファイルを使って、エンジンごとの認識結果の違いを確認しよう。
レポート
- 実習1の課題で作ったSSML。簡単に工夫したポイントについて述べてください。
-
実習2の課題
2-1. 課題1の実行結果(Julius / Kaldi / Google Speech to Text)
2-2. 課題2の実行結果(Julius / Kaldi / Google Speech to Text)
2-3. 音声認識ソフトウェアの認識結果の違いはなぜ生まれるのかの考察